
MDFL
1 Year Ago
#1
BrainFlood: Runtime code generation via reflection in .NET : churchofmiku/brainflood/news/brainflood-compiling-via-reflection-8089c180




int x = 3 * 3 * 3 * 3 * 5 * 5; // simplifies to: int x = 2025;
int Add(int x, int y) {
return x + y;
}
int Add3(int x, int y, int z) {
return Add(Add(x,y),z);
}
// the second function can be optimized to:
int Add3(int x, int y, int z) {
return x + y + z;
}int Five() {
return 5;
}
int Fifteen() {
return Five()+Five()+Five();
}
// the second function can be optimized to:
int Fifteen() {
return 15;
}static T Min<T>(T a, T b) where T: IComparable {
if (a.CompareTo(b)<0) {
return a;
} else {
return b;
}
}using System.Runtime.CompilerServices;
interface Number {
static abstract int Eval();
}
class ConstDead : Number {
public static int Eval() {
return 0xDEAD;
}
}
class ConstBeef : Number {
public static int Eval() {
return 0xBEEF;
}
}
class Concat<A,B> : Number
where A: Number
where B: Number
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static int Eval() {
return (A.Eval() << 16) + B.Eval();
}
}
class Example {
int Run() {
return Concat<ConstDead,ConstBeef>.Eval();
}
} L0000: mov eax, 0xdeadbeef
L0005: retusing System.Runtime.CompilerServices;
interface Number {
int Eval();
}
struct ConstDead : Number {
public int Eval() {
return 0xDEAD;
}
}
struct ConstBeef : Number {
public int Eval() {
return 0xBEEF;
}
}
struct Concat<A,B> : Number
where A: struct, Number
where B: struct, Number
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public int Eval() {
return (default(A).Eval() << 16) + default(B).Eval();
}
}
class Example {
int Run() {
return default(Concat<ConstDead,ConstBeef>).Eval();
}
}interface Const {
int Run();
}
// Single Hex Digits
struct D0 : Const { public int Run() => 0; }
struct D1 : Const { public int Run() => 1; }
struct D2 : Const { public int Run() => 2; }
// D3 - DD omitted
struct DE : Const { public int Run() => 0xE; }
struct DF : Const { public int Run() => 0xF; }
// Two Hex Digits
struct Num<A,B> : Const
where A: struct, Const
where B: struct, Const
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public int Run() {
return default(A).Run()<<4 | default(B).Run();
}
}
// Negatives
struct Neg<A> : Const
where A: struct, Const
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public int Run() {
return -default(A).Run();
}
}class Example {
int Run() {
return default(Neg<Num<D2,DF>>).Run();
}
}
// compiles to
L0000: mov eax, 0xffffffd1
L0005: retinterface Op {
int Run(int index, byte[] data, Output output);
}
struct ZeroCell<OFFSET,NEXT> : Op
where OFFSET: struct, Const
where NEXT: struct, Op
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public int Run(int index, byte[] data, Output output)
{
data[index + default(OFFSET).Run()] = 0;
return default(NEXT).Run(index, data, output);
}
}struct Stop : Op
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public int Run(int index, byte[] data, Output output)
{
return index;
}
}struct UpdatePointer<OFFSET,NEXT> : Op
where OFFSET: struct, Const
where NEXT: struct, Op
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public int Run(int index, byte[] data, Output output)
{
index += default(OFFSET).Run();
return default(NEXT).Run(index, data, output);
}
}struct Loop<BODY,NEXT> : Op
where BODY: struct, Op
where NEXT: struct, Op
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public int Run(int index, byte[] data, Output output)
{
var body = default(BODY);
while (data[index] != 0) {
output.CheckKill();
index = body.Run(index, data, output);
}
return default(NEXT).Run(index, data, output);
}
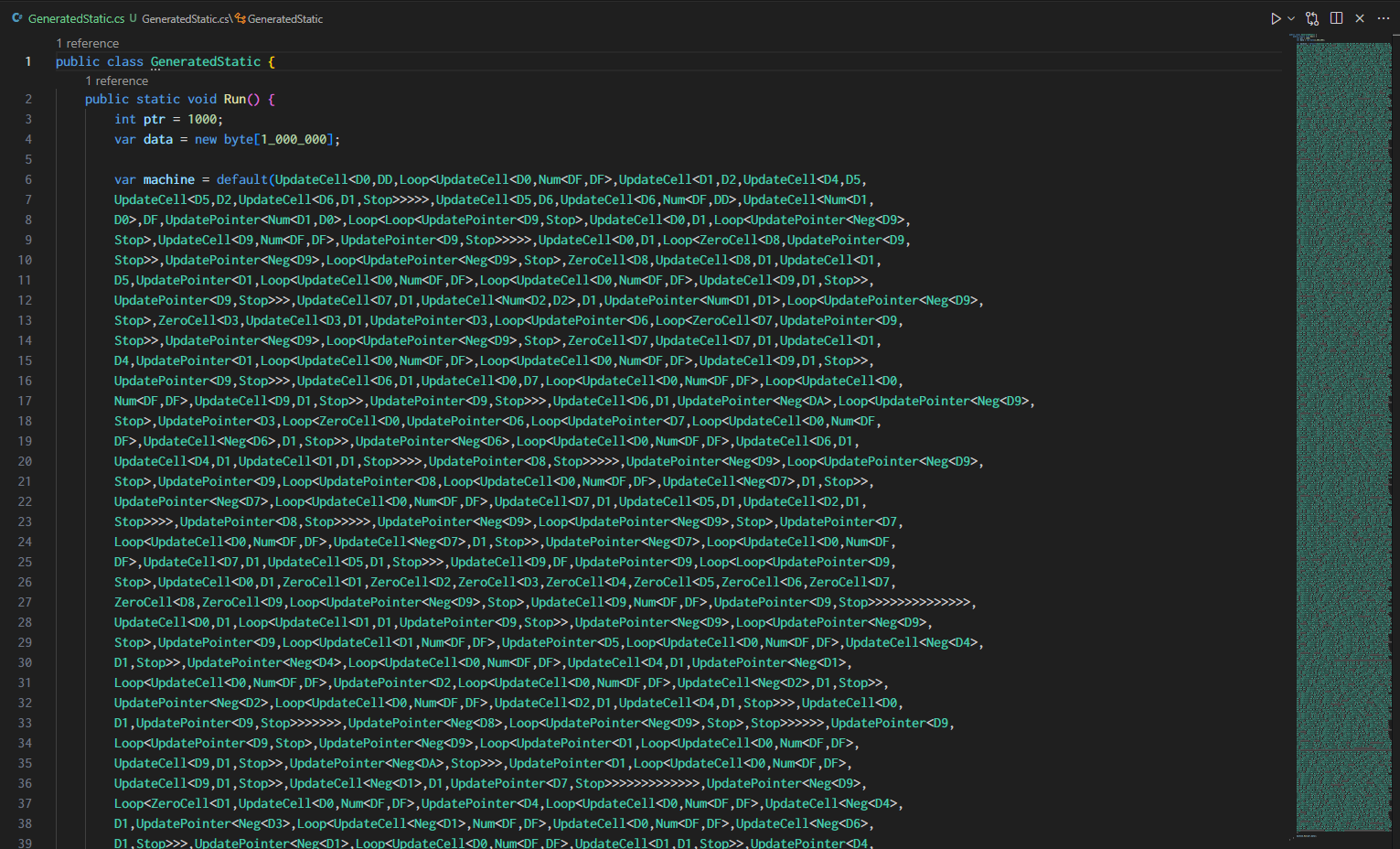
}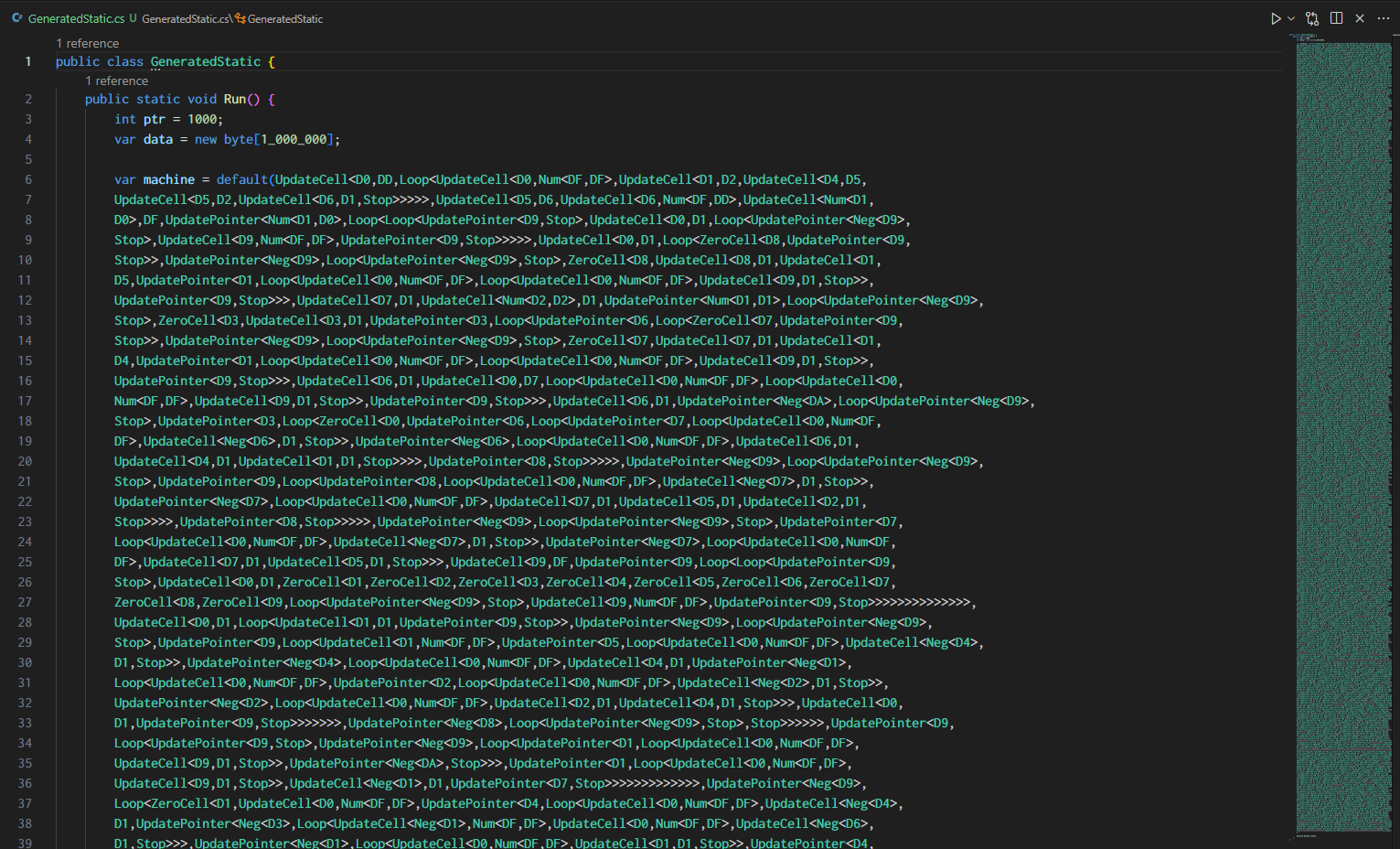
private static Type MakeGeneric(Type base_ty, Type[] args) {
return TypeLibrary.GetType(base_ty).MakeGenericType(args);
}
private static Type GetDigit(int n) {
switch (n) {
case 0: return typeof(D0);
case 1: return typeof(D1);
case 2: return typeof(D2);
case 3: return typeof(D3);
case 4: return typeof(D4);
case 5: return typeof(D5);
case 6: return typeof(D6);
case 7: return typeof(D7);
case 8: return typeof(D8);
case 9: return typeof(D9);
case 0xA: return typeof(DA);
case 0xB: return typeof(DB);
case 0xC: return typeof(DC);
case 0xD: return typeof(DD);
case 0xE: return typeof(DE);
case 0xF: return typeof(DF);
}
throw new Exception("die");
}
private static Type GenerateConst(int n) {
if (n < 0) {
return MakeGeneric(typeof(Neg<>),[GenerateConst(-n)]);
}
if (n < 16) {
return GetDigit(n);
} else if (n < 256) {
return MakeGeneric(typeof(Num<,>),[GetDigit(n>>4),GetDigit(n&0xF)]);
} else {
throw new Exception("const too large "+n);
}
} trophy 2085
trophy 2085 trophy 335
trophy 335