Earlier this year, I discovered a very silly way to compile brainfuck to native code on the .NET runtime. It's not all that useful to the average programmer, but it is a reasonably fast and safe way to run user-supplied code in s&box's sandboxed environment. But I had at least two problems:
Brainfuck is a very unfun language to program in.
Brainfuck is a very inefficient language to execute.
I decided WebAssembly would be the best way to run real programs. Despite the "web" in the name, WebAssembly is really just a compact, low-level bytecode format that you can run just about anywhere. I decided to call this thing MirrorVM, because it uses reflection, and because I am not creative.
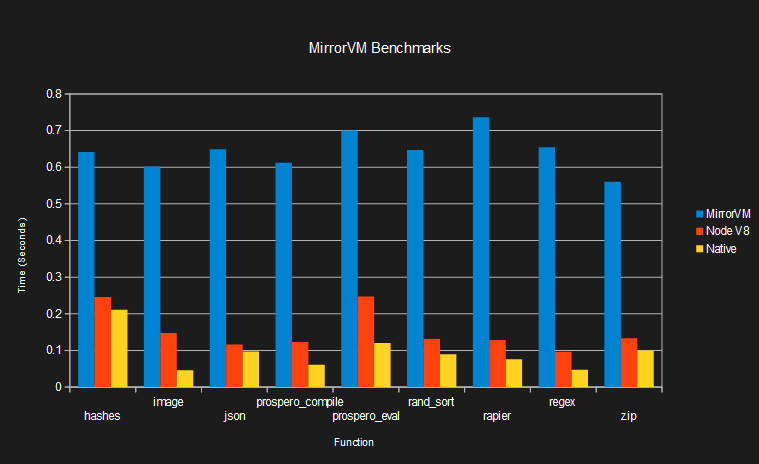
One of my main goals was performance. How did I do? For context, I wrote my own little benchmark suite. It consists of a few functions from some popular rust crates (compression, regex, json, physics) and a really bad prospero challenge evaluator I wrote. Each function is called 10 times, and the fastest time is used. This should favor JITs, which includes MirrorVM and every other decent WebAssembly runtime. I'm sure my methodology isn't perfect, but it should be good enough to draw some simple conclusions.
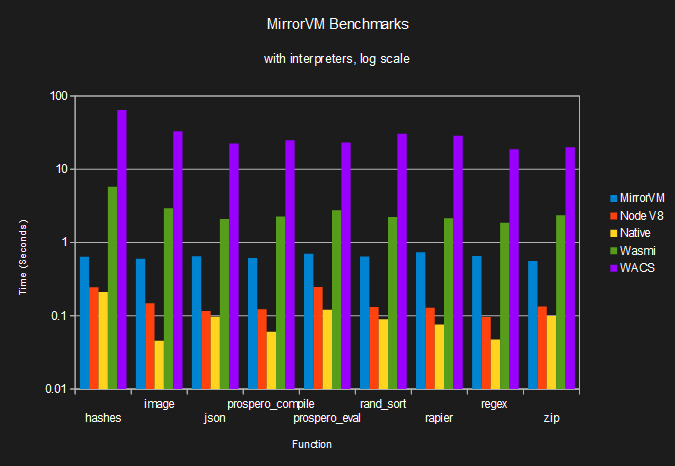
So, MirrorVM is about 3-5 times slower than V8, and 3-14 times slower than native. It's slow for a compiler, but is a compiler! Here's another comparison with some interpreters: MirrorVM runs my benchmarks 3-9 times faster than Wasmi, which I believe is the fastest WebAssembly interpreter. It runs them 100-230 times faster than WACS, a .NET-based interpreter.
I don't want to disparage WACS though. It supports many more features, more platforms, has a cleaner API, is better tested, is probably less buggy, and doesn't rely on insane, un-debuggable type system abuse. It seems like a very nice library, and I'd recommend it over MirrorVM if you want WebAssembly plugins in a .NET app and are okay with relatively bad performance. If you want speed and you aren't trying to run code in a very specific sandboxed jail, you should probably use .NET bindings to a good native runtime.
Rileyzzz's AOT compiler may also be faster than MirrorVM, and I have been provided a build to benchmark, but I haven't gotten around to it (Sorry!).
The techniques I use build on the ideas from my last post. In summary: I create a very large generic type, and pray that .NET's JIT will perform enough inlining and other optimizations to generate good code.
WebAssembly poses several challenges not present when dealing with Brainfuck. Primarily:
Data Flow: Brainfuck really only has one value to keep track of, the current pointer. WebAssembly is a stack machine where most operations produce a value, and there can be an unlimited number of local and global variables.
Control Flow: Brainfuck has one control flow mechanism, which is similar to a while loop. WebAssembly allows you to jump around in a much more flexible fashion. It's still limited to structured control flow between blocks, but that only helps so much.
I'll expand on these problems and my solutions in the following sections.
WebAssembly is a stack machine, but executing code on a stack machine is quite slow compared to the alternatives. Every compiler and most good interpreters convert the stack abstraction into something faster.
MirrorVM converts the stack code into a series of Expressions and Statements. An Expression is a typed operation that produces a value with no side-effects. Expressions optimize really well: the JIT is usually able to keep temporaries in registers. Here are some examples of expressions in pseudo-code:
(local_1 + local_2) / 2 // type f32
global_1 - 64 // type i32
memory[memory[local_1] * 8] + 3 // type i64 (the inner expression is type i32)
A Statement is an assignment of an Expression to a Destination, or some other operation with side-effects, like a function call. Statements are executed sequentially.
local_3 = (local_1 + local_2) / 2 // type f32
global_1 = global_1 - 64 // type i32
memory[local_0] = memory[memory[local_1] * 8] + 3 // type i64 (the inner expression is type i32)
call foo
These statements should get converted to the following MirrorVM types. Arguments to constant expressions were omitted for clarity. They are built with D0...DF, Num, and Neg structs similar to the BrainFlood article.
SetR3_F32< Op_F32_Div< Op_F32_Add<GetR1_F32,GetR2_F32>, Const_F32< /* 2 */> >
// Globals use constant indices.
SetGlobal_I32<D1, Op_I32_Sub< GetGlobal_I32<D1>, Const_I32< /* 64 */> > >
// Memory operations have a constant offset as their last parameter.
Memory_I64_Store<
Op_I64_Add< Memory_I64_Load<
Op_I32_Mul< Memory_I32_Load< GetR1_I32, D0 >, Const_I32< /* 8 */> >,
D0 >, Const_I64< /* 3 */> >
, GetR0_I32, D0 >
// Calls will be explained in more depth later.
StaticCall<D8,DC>
The implementation of these types is about as stupid as you'd expect:
// Example expression definition
interface Expr<T>
{
T Run( ref Registers reg, Span<long> frame, WasmInstance inst );
}
struct Op_I64_Add<A, B> : Expr<long> where A : struct, Expr<long> where B : struct, Expr<long>
{
[MethodImpl( MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization )]
public long Run( ref Registers reg, Span<long> frame, WasmInstance inst ) =>
default( A ).Run( ref reg, frame, inst ) + default( B ).Run( ref reg, frame, inst );
}
// Example statement definition
interface Stmt
{
void Run( ref Registers reg, Span<long> frame, WasmInstance inst );
}
struct SetGlobal_I32<INDEX, VALUE> : Stmt where INDEX : struct, Const where VALUE : struct, Expr<int>
{
[MethodImpl( MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization )]
public void Run( ref Registers reg, Span<long> frame, WasmInstance inst )
{
inst.Globals[(int)default( INDEX ).Run()] =
(uint)default( VALUE ).Run( ref reg, frame, inst );
}
}
Finally, for a "real" example, here's some IR from one of my benchmarks:
MirrorVM has two tiers of local variables: Registers and Frame variables. All locals and globals are stored as 64 bit integers and bit casted to the correct type where needed. Registers are a bundle of 7 values stored in a struct, unique to each function invocation:
struct Registers
{
public long R0;
public long R1;
public long R2;
public long R3;
public long R4;
public long R5;
public long R6;
public int NextBlock;
}
// Sample f32 register operations
struct GetR0_F32 : Expr<float> {
public float Run( ref Registers reg, Span<long> frame, WasmInstance inst ) =>
BitConverter.Int32BitsToSingle( (int)reg.R0 );
}
struct SetR2_F32<VALUE> : Stmt where VALUE : struct, Expr<float>
{
[MethodImpl( MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization )]
public void Run( ref Registers reg, Span<long> frame, WasmInstance inst )
{
reg.R2 = BitConverter.SingleToUInt32Bits( default( VALUE ).Run( ref reg, frame, inst ) );
}
}
The hope was that these registers would be mapped to real hardware registers. In theory, the .NET JIT is capable of this. Sadly, it seems that this will fail entirely if the registers are passed between functions that fail to inline, which happens all the time. Still, using these pseudo-registers does seem to yield slightly better performance. I did not actually bother with smart register allocation. Registers are just mapped to the first 7 locals in a function.
The Frame stores the rest of the locals, and it's just a big span of longs. The operations work exactly how you'd expect.
struct SetFrame_F32<INDEX, VALUE> : Stmt where INDEX : struct, Const where VALUE : struct, Expr<float>
{
[MethodImpl( MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization )]
public void Run( ref Registers reg, Span<long> frame, WasmInstance inst )
{
frame[(int)default( INDEX ).Run()] =
BitConverter.SingleToUInt32Bits( default( VALUE ).Run( ref reg, frame, inst ) );
}
}
This means your average C or Rust WebAssembly module on MirrorVM has at least three stacks: the native call stack, the shadow stack inside the WebAssembly memory, and the Frame stack. In earlier versions I experimented with stackallocing a frame for each function, but doing this made function calls more complicated.
The beginning and end of each frame are shared between function calls and used to pass function arguments and return values. In a function with two arguments and one return value, F0 stores the return value, F1 stores the first argument, and F2 stores the second argument.
I was worried it might be challenging to implement fast loads and stores for various types. I did some very stupid things in my Lua WebAssembly runtime. Fortunately, .NET makes it easy.
The extra bounds checks for stores look gross, but it doesn't seem to affect performance much. The main issue is that WebAssembly has many different memory instructions for different widths and signs, so there are 23 of these things.
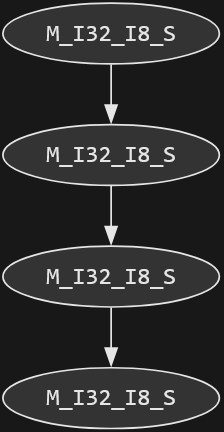
The single most critical aspect of MirrorVM's performanc is function inlining. The more functions the JIT inlines together into a single native function, the better. When I was investigating JIT dumps, I found something weird. Often, there are many statements of the same kind in a row:At this point, statements worked the same way as in Brainflood. Each statement had a NEXT parameter which a statement calls when it is finished. In many cases, a statement would fail to inline another statement of the same type. After some hacking on the dotnet source code, I discovered the culprit. The inliner has rules against recursion on large generic types. I don't fully understand the rationale for this, but it wasn't hard to fix. First, I use trees for statements instead of chains. I created a Stmts bundle type that holds four statements.But wait! There's still recursion on the bundle types! I fixed this by introducing many identical bundle types and using a different one for each level of the tree:Sadly, most other inlining failures just had to do with the size limitations, which are hard to get around. There are some conditions for always inlining, but they seem impossible to achieve for arbitrary methods.
Control flow is hard. If all code was if statements and while loops, it would be easy. But in real code, we can enter several nested loops and conditionals, then break, continue, or return from inside them. The Relooper and Stackifier algorithms were invented to solve these types of problems, but both require a break construct. We could throw exceptions to handle these constructs, but that would be extremely expensive.
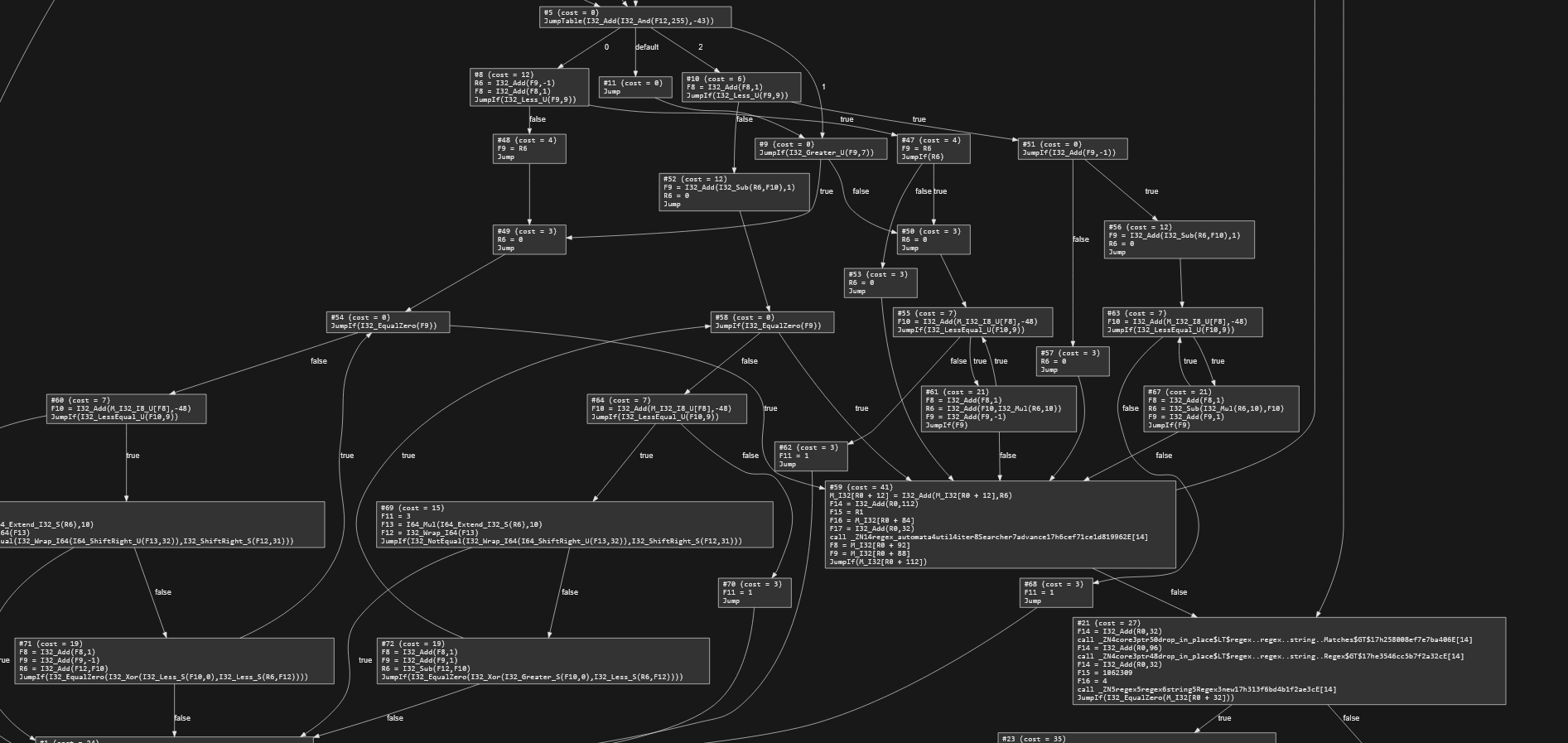
First, we need to think about code in terms of basic blocks. A basic block is is a sequence of code with no branches. There can be multiple branches in at the beginning, and multiple branches out at the end, but no branches out in the middle, and no way to branch in to the middle. In MirrorVM, each basic block contains a list of statements and a terminator. The terminator determines what to do at the end of the block: branch somewhere, return, or trap (throw an exception). From the basic blocks, we can construct a control flow graph for a given function. Most optimizing compilers do something like this.
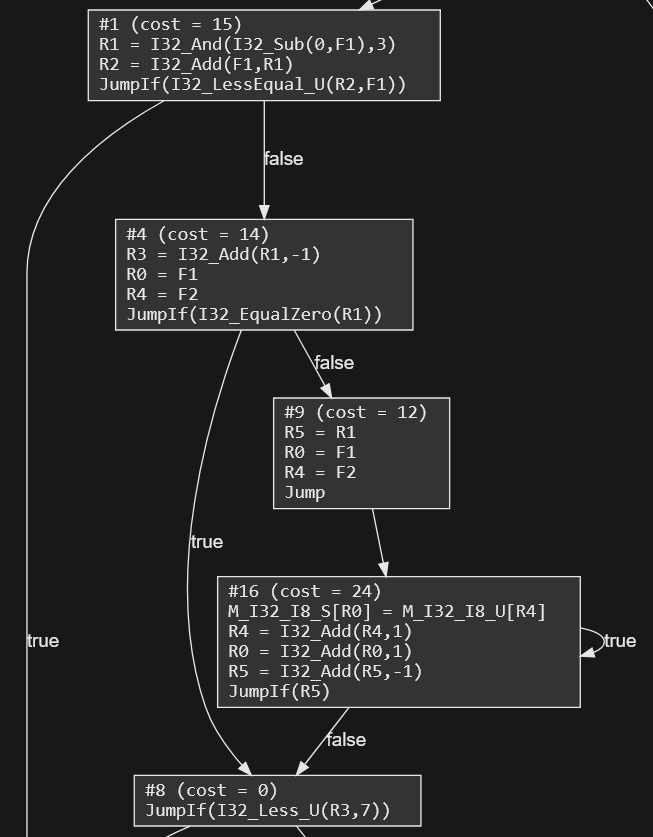
Here's part of a control flow graph from memcpy:You can see several branches, as well as a loop -- the block near the bottom with a small arrow pointing to itself.
So, what are we going to do with these basic blocks? I'm afraid it's not that impressive:
struct DispatchLoop10<
B0, B1, B2, B3, B4, B5, B6, B7, B8, B9
> : Stmt
where B0 : struct, Terminator where B1 : struct, Terminator where B2 : struct, Terminator where B3 : struct, Terminator where B4 : struct, Terminator
where B5 : struct, Terminator where B6 : struct, Terminator where B7 : struct, Terminator where B8 : struct, Terminator where B9 : struct, Terminator
{
[MethodImpl( MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization )]
public void Run( ref Registers reg, Span<long> frame, WasmInstance inst )
{
for (; ; )
{
switch ( reg.NextBlock )
{
case 0: default( B0 ).Run( ref reg, frame, inst ); break;
case 1: default( B1 ).Run( ref reg, frame, inst ); break;
case 2: default( B2 ).Run( ref reg, frame, inst ); break;
case 3: default( B3 ).Run( ref reg, frame, inst ); break;
case 4: default( B4 ).Run( ref reg, frame, inst ); break;
case 5: default( B5 ).Run( ref reg, frame, inst ); break;
case 6: default( B6 ).Run( ref reg, frame, inst ); break;
case 7: default( B7 ).Run( ref reg, frame, inst ); break;
case 8: default( B8 ).Run( ref reg, frame, inst ); break;
case 9: default( B9 ).Run( ref reg, frame, inst ); break;
default: return;
}
}
}
}
It's just a dispatch loop like you'd find in an interpreter. But instead of switching on opcodes, we switch on block indices. Terminators write to Registers.NextBlock to tell the loop what to do. Returns indicate a return by writing -1.
There are several kinds of dispatch loop: sizes that can hold 10, 25, 50, 100, and 200 blocks. There's also a fallback, DispatchLoopArray, which can hold an arbitrary number of terminators in an array.
One small benefit of this scheme is that br_table / jump table / switch-case constructs can be easily take advantage of the existing dispatch table:
struct TermJumpTable<SEL, BASE, COUNT, BODY> : Terminator
where SEL : struct, Expr<int>
where BASE : struct, Const
where COUNT : struct, Const
where BODY : struct, Stmt
{
[MethodImpl( MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization )]
public void Run( ref Registers reg, Span<long> frame, WasmInstance inst )
{
default( BODY ).Run( ref reg, frame, inst );
uint sel = (uint)default( SEL ).Run( ref reg, frame, inst );
uint base_block = (uint)default( BASE ).Run();
uint max = (uint)default( COUNT ).Run() - 1;
reg.NextBlock = (int)(base_block + uint.Min( sel, max ));
}
}
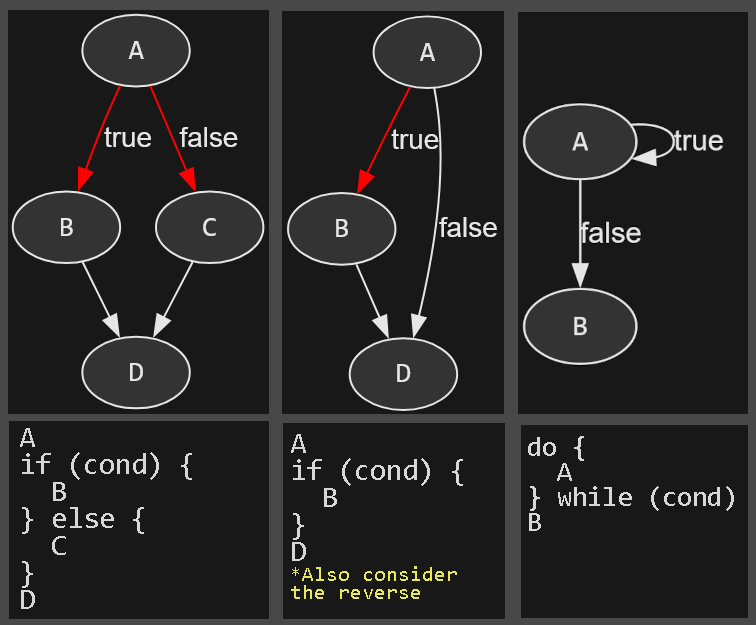
Recovering nice structured control flow for all functions is probably impossible, but we can at least try. There are a few simple cases that can be translated.Each graph can be converted into the code below it. A red edge indicates an exclusive inbound jump (there are no other ways to reach the block). MirrorVM just iterates backwards through the graph, rewriting everything it can.
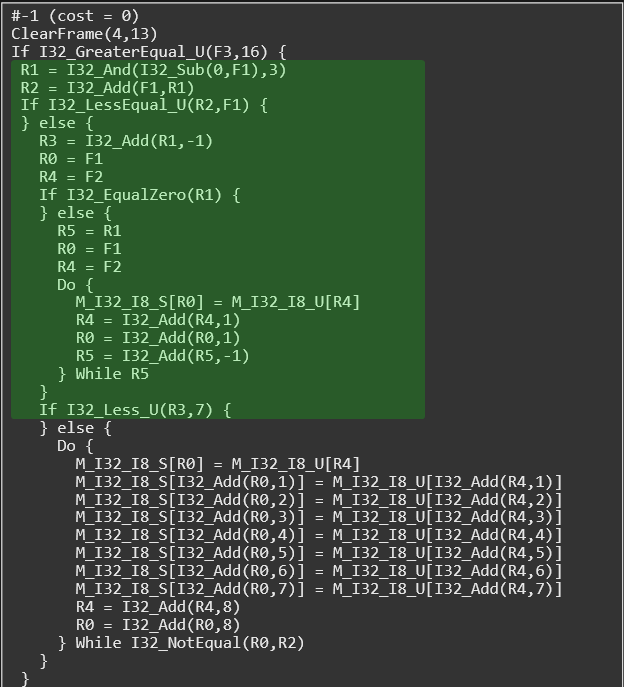
This process was applied to the memcpy function from earlier, with the previous section marked in green.In fact, these simple rules are enough to completely re-structure the function into a single block! More complex functions rarely work this well, though.
I believe some additional rules could be added, to merge block terminators together. This would remove the requirement that both sides of an if need to lead to the same place. I was not able to summon the motivation to do this after many other failed optimization efforts. Which brings us to:
Ultimately, I never solved the data flow or control flow problems as well as I had hoped. These two problems are related: good enough control over inlining might allow a Registers struct to lower to native registers, while the control flow strategy might help or hinder inlining performance. In this section I'll list some ideas I had that didn't work out.
Block Splitting
The inlining heuristics are probably impossible to defeat, but what if they can be predicted? Often, MirrorVM will inline code in a way that looks a little like this:The nodes here can be anything: bundles, statements, expressions, or constants. Red edges indicate a failure to inline. In the worst case, individual nibbles of a 64 bit constant fail to inline, and you end up with 16 function calls for what should be a constant value.
It might be nice to group statements into chunks that we know will inline together, and explicitly break them up with MethodImplOptions.NoInlining. I spent a lot of time on this, and it never seemed to help. Combining it with the structured control flow recovery only made it more difficult. I never considered the outer dispatch loop, which I suspect was a big mistake.
Optimizing for Size
This involves tweaking how the WebAssembly modules are built. Some aggressive optimizations, like loop unrolling, end up generating more code. More code is bad, because it results in more functions that fail to inline. Rustc has several optimization levels that prioritize generating small code instead of fast code. I tried using them, but they did not seem to help.
JIT Compilation
I had another hilarious idea. What if I run my own JIT on top of .NET's JIT? Since control flow is hard, maybe hot paths can be optimized for. Maybe the inliner will be more happy if we compile a bunch of hot blocks together.
The technique I tried was a little bit like a tracing JIT: Once a block is entered a certain number of times, replace it with a linear trace block. The trace block can end in a loop, and can exit at arbitrary points. Sadly the JIT bookkeeping and slower array-based dispatch were just too slow to make up for any improvements. Maybe some kind of whole-method approach would work better.
Taking Advantage of .NET's JIT Tiering / PGO???
This is a subject I've done very little research on. Modern .NET is a tiered JIT compiler. It does the same thing I describe above, but way better. Maybe it can make smarter decisions about inlining. Maybe it already does, and I'm a huge fool. One possible issue is that MirrorVM uses aggressive inlining, which opts out of some of this potential optimization. Honestly, I'm not entirely sure how these things interact. I probably need to do more reading, and I might need better profiling tools.
As I've said before, in the end I'm just a compiler hobbyist. I'm somewhat allergic to reading acadamic papers, which probably holds me back a lot. If you have any crazy ideas for making this thing run faster, I'd love to hear them!
Once I built this piece of garbage, I realized I needed to build something else to show off its capabilities.
Implementing WASI didn't sound fun to me. I want to play games, not fool around with file descriptors.
WASM-4 is a really neat little fantasy console. It only requires a handful of functions and memory-mapped registers. The frame buffer lives inside the VM's memory and gets copied out each frame. It didn't take much effort to get it working. It helps that I copied some code from the JavaScript runtime, and I neglected to implement audio, persistence, and multiplayer features. Also, some games are broken, so there are probably still some bugs in MirrorVM. 😅
Besides what I've already mentioned, there are a few improvements I'd like to make.
More WebAssembly Extensions
MirrorVM only supports a few simple extensions: multi-value, bulk memory, and non-trapping float-to-int.
SIMD would be fun to try. I'm curious to see whether WASM SIMD semantics map on to System.Numerics.Vector, and how fast they would run if so.
Garbage Collection could also be neat. .NET already has a GC. How hard could it be? It might be useful for supporting lightweight, garbage collected languages, but I'm not sure if any languages actually fit that description and use wasm gc as a target.
The main challenge with both of these is that they introduce types that can't be shoved inside a long. Maybe SIMD could use a pair of longs, but garbage collection actually needs reference types.
Limits on User Code
For the most part, MirrorVM can run user code safely. What it can't currently do is guard against denial of service. It will happily let a module exhaust your memory, or loop forever. It shouldn't be hard to add these limitations.
Asyncification
The ability to pause and resume execution could also be nice. Maybe there could even be an option to pause user code when it hits a limit, then resume it next frame. Emscripten and Rileyzzz's DEXtr can do it, and I don't think it would be that hard to add to MirrorVM.
More Demos
I'd like to try running some more advanced games. OpenTTD is probably my next target for annihilation. It's one of the first games I remember seeing compiled to javascript, and it's just an incredible little game.
Beyond that, maybe something 3D to really test the limits. I could try the Cube 2 engine, or maybe some other open source shooter. Veloren would be hilarious, but I don't know if it's doable. Half Life would be incredibly cool, and might even be possible via the xash3d engine.