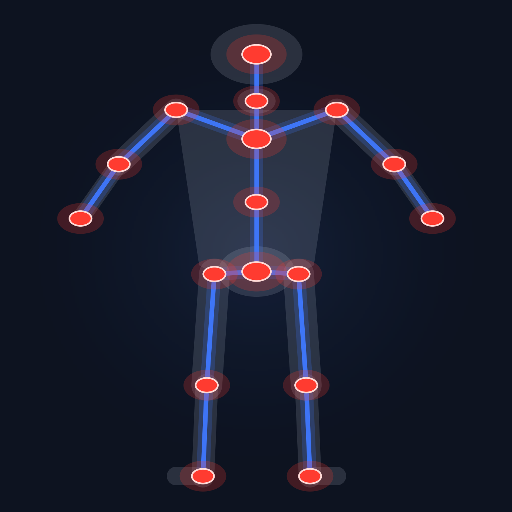
Auto Rigger
Released
deep-learning auto-rigger for s&box. Rig Everything. (experimental)
AutoRig/Dl/Nn/TransformerOps.cs
Neural network transformer utility functions for inference. Implements LayerNorm, RMSNorm, GELU variants, SiLU, attention (standard and grouped-query), rotary embeddings, per-head RMSNorm, SwiGLU, embedding lookup, argmax, and an Erf approximation operating on a Tensor type.
namespace AutoRig.Dl.Nn;
using AutoRig.Dl;
/// <summary>
/// Transformer building blocks over <see cref="Tensor"/> ([N, C] rows), matching
/// PyTorch inference semantics (eps defaults, tanh-approx GELU where models use it).
/// Foundation for the UniRig-family ports (plan 8).
/// </summary>
public static class TransformerOps
{
/// <summary>LayerNorm over the last dim: (x - mean) / sqrt(var + eps) * g + b.</summary>
public static Tensor LayerNorm( Tensor x, Tensor gamma, Tensor beta, float eps = 1e-5f )
{
var (rows, cols) = (x.Shape[0], x.Shape[1]);
var result = new float[x.Count];
for ( var r = 0; r < rows; r++ )
{
float mean = 0;
for ( var c = 0; c < cols; c++ )
mean += x.Data[r * cols + c];
mean /= cols;
float variance = 0;
for ( var c = 0; c < cols; c++ )
{
var d = x.Data[r * cols + c] - mean;
variance += d * d;
}
variance /= cols;
var inv = 1f / MathF.Sqrt( variance + eps );
for ( var c = 0; c < cols; c++ )
result[r * cols + c] =
(x.Data[r * cols + c] - mean) * inv * (gamma?.Data[c] ?? 1f)
+ (beta?.Data[c] ?? 0f); // null = no affine (DiT final norm)
}
return Tensor.From( result, rows, cols );
}
/// <summary>RMSNorm: x / rms(x) * g (LLaMA-style, no mean subtraction).</summary>
public static Tensor RmsNorm( Tensor x, Tensor gamma, float eps = 1e-6f )
{
var (rows, cols) = (x.Shape[0], x.Shape[1]);
var result = new float[x.Count];
for ( var r = 0; r < rows; r++ )
{
float meanSquare = 0;
for ( var c = 0; c < cols; c++ )
{
var v = x.Data[r * cols + c];
meanSquare += v * v;
}
meanSquare /= cols;
var inv = 1f / MathF.Sqrt( meanSquare + eps );
for ( var c = 0; c < cols; c++ )
result[r * cols + c] = x.Data[r * cols + c] * inv * gamma.Data[c];
}
return Tensor.From( result, rows, cols );
}
/// <summary>Exact GELU: x · Φ(x) via erf (PyTorch nn.GELU default).</summary>
public static Tensor Gelu( Tensor x )
{
var result = new float[x.Count];
for ( var i = 0; i < x.Count; i++ )
result[i] = x.Data[i] * 0.5f * (1f + Erf( x.Data[i] * 0.70710678f ));
return Tensor.From( result, x.Shape );
}
/// <summary>Tanh-approximated GELU (PyTorch approximate="tanh" / GPT-style).</summary>
public static Tensor GeluTanh( Tensor x )
{
var result = new float[x.Count];
for ( var i = 0; i < x.Count; i++ )
{
var v = x.Data[i];
result[i] = 0.5f * v * (1f + MathF.Tanh(
0.7978845608f * (v + 0.044715f * v * v * v) ));
}
return Tensor.From( result, x.Shape );
}
/// <summary>SiLU / swish: x · sigmoid(x).</summary>
public static Tensor Silu( Tensor x )
{
var result = new float[x.Count];
for ( var i = 0; i < x.Count; i++ )
result[i] = x.Data[i] / (1f + MathF.Exp( -x.Data[i] ));
return Tensor.From( result, x.Shape );
}
/// <summary>
/// Multi-head scaled-dot-product attention. q: [Nq, H·D], k/v: [Nk, H·D]
/// (already projected). Causal masks query i from keys j > i + (Nk − Nq)
/// (standard KV-cache offset). Returns [Nq, H·D].
/// </summary>
public static Tensor Attention( Tensor q, Tensor k, Tensor v, int heads, bool causal )
{
var nq = q.Shape[0];
var nk = k.Shape[0];
var headDim = q.Shape[1] / heads;
var scale = 1f / MathF.Sqrt( headDim );
var offset = nk - nq;
var result = new float[nq * heads * headDim];
void Head( int h )
{
var scores = new float[nk]; // per-worker buffer
var headBase = h * headDim;
for ( var i = 0; i < nq; i++ )
{
var limit = causal ? Math.Min( nk, i + offset + 1 ) : nk;
var max = float.MinValue;
for ( var j = 0; j < limit; j++ )
{
float dot = 0;
for ( var d = 0; d < headDim; d++ )
dot += q.Data[i * heads * headDim + headBase + d]
* k.Data[j * heads * headDim + headBase + d];
scores[j] = dot * scale;
if ( scores[j] > max )
max = scores[j];
}
float total = 0;
for ( var j = 0; j < limit; j++ )
{
scores[j] = MathF.Exp( scores[j] - max );
total += scores[j];
}
for ( var j = 0; j < limit; j++ )
{
var weight = scores[j] / total;
if ( weight == 0f )
continue;
for ( var d = 0; d < headDim; d++ )
result[i * heads * headDim + headBase + d] +=
weight * v.Data[j * heads * headDim + headBase + d];
}
}
}
// Heads write disjoint column ranges — safe to parallelize; skip the
// overhead for tiny single-token decode steps.
if ( (long)nq * nk * headDim >= 1 << 16 )
Concurrency.For( 0, heads, Head );
else
for ( var h = 0; h < heads; h++ )
Head( h );
return Tensor.From( result, nq, heads * headDim );
}
/// <summary>
/// Rotary position embedding (LLaMA/Qwen half-split convention): for each head,
/// x' = x·cos(θ) + rotate_half(x)·sin(θ) with rotate_half = (−x₂, x₁) over the
/// half-dim split; θ_i = pos · base^(−2i/d).
/// </summary>
public static Tensor Rope( Tensor x, int heads, int[] positions, float thetaBase = 1e6f )
{
var rows = x.Shape[0];
var headDim = x.Shape[1] / heads;
var half = headDim / 2;
var result = new float[x.Count];
var invFreq = new float[half];
for ( var i = 0; i < half; i++ )
invFreq[i] = MathF.Pow( thetaBase, -2f * i / headDim );
for ( var r = 0; r < rows; r++ )
for ( var h = 0; h < heads; h++ )
{
var at = r * heads * headDim + h * headDim;
for ( var i = 0; i < half; i++ )
{
var angle = positions[r] * invFreq[i];
var (sin, cos) = (MathF.Sin( angle ), MathF.Cos( angle ));
var a = x.Data[at + i];
var b = x.Data[at + half + i];
result[at + i] = a * cos - b * sin;
result[at + half + i] = b * cos + a * sin;
}
}
return Tensor.From( result, rows, heads * headDim );
}
/// <summary>
/// Grouped-query attention: q has <paramref name="qHeads"/>, k/v have
/// <paramref name="kvHeads"/> (each kv head serves qHeads/kvHeads queries).
/// Same causal/KV-cache-offset semantics as <see cref="Attention"/>.
/// </summary>
public static Tensor AttentionGqa(
Tensor q, Tensor k, Tensor v, int qHeads, int kvHeads, bool causal )
{
var nq = q.Shape[0];
var nk = k.Shape[0];
var headDim = q.Shape[1] / qHeads;
var scale = 1f / MathF.Sqrt( headDim );
var offset = nk - nq;
var group = qHeads / kvHeads;
var result = new float[nq * qHeads * headDim];
void Head( int h )
{
var scores = new float[nk];
var kvHead = h / group;
var qBase = h * headDim;
var kvBase = kvHead * headDim;
for ( var i = 0; i < nq; i++ )
{
var limit = causal ? Math.Min( nk, i + offset + 1 ) : nk;
var max = float.MinValue;
for ( var j = 0; j < limit; j++ )
{
float dot = 0;
for ( var d = 0; d < headDim; d++ )
dot += q.Data[i * qHeads * headDim + qBase + d]
* k.Data[j * kvHeads * headDim + kvBase + d];
scores[j] = dot * scale;
if ( scores[j] > max )
max = scores[j];
}
float total = 0;
for ( var j = 0; j < limit; j++ )
{
scores[j] = MathF.Exp( scores[j] - max );
total += scores[j];
}
for ( var j = 0; j < limit; j++ )
{
var weight = scores[j] / total;
if ( weight == 0f )
continue;
for ( var d = 0; d < headDim; d++ )
result[i * qHeads * headDim + qBase + d] +=
weight * v.Data[j * kvHeads * headDim + kvBase + d];
}
}
}
if ( (long)nq * nk * headDim >= 1 << 16 )
Concurrency.For( 0, qHeads, Head );
else
for ( var h = 0; h < qHeads; h++ )
Head( h );
return Tensor.From( result, nq, qHeads * headDim );
}
/// <summary>Per-head RMSNorm over each head's slice (Qwen3 q_norm/k_norm).</summary>
public static Tensor RmsNormPerHead( Tensor x, Tensor gamma, int heads, float eps = 1e-6f )
{
var rows = x.Shape[0];
var headDim = x.Shape[1] / heads;
var result = new float[x.Count];
for ( var r = 0; r < rows; r++ )
for ( var h = 0; h < heads; h++ )
{
var at = r * heads * headDim + h * headDim;
float meanSquare = 0;
for ( var d = 0; d < headDim; d++ )
meanSquare += x.Data[at + d] * x.Data[at + d];
var inv = 1f / MathF.Sqrt( meanSquare / headDim + eps );
for ( var d = 0; d < headDim; d++ )
result[at + d] = x.Data[at + d] * inv * gamma.Data[d];
}
return Tensor.From( result, rows, heads * headDim );
}
/// <summary>SwiGLU feed-forward core: silu(gate) ⊙ up (caller applies down proj).</summary>
public static Tensor SwiGlu( Tensor gate, Tensor up )
{
var result = new float[gate.Count];
for ( var i = 0; i < gate.Count; i++ )
result[i] = gate.Data[i] / (1f + MathF.Exp( -gate.Data[i] )) * up.Data[i];
return Tensor.From( result, gate.Shape );
}
/// <summary>Embedding lookup: ids → rows of the [V, C] table.</summary>
public static Tensor Embed( Tensor table, int[] ids )
{
var cols = table.Shape[1];
var result = new float[ids.Length * cols];
for ( var i = 0; i < ids.Length; i++ )
Array.Copy( table.Data, ids[i] * cols, result, i * cols, cols );
return Tensor.From( result, ids.Length, cols );
}
/// <summary>Greedy decode step: argmax of the final row of logits.</summary>
public static int Argmax( Tensor logits )
{
var cols = logits.Shape[1];
var lastRow = (logits.Shape[0] - 1) * cols;
var best = 0;
for ( var c = 1; c < cols; c++ )
if ( logits.Data[lastRow + c] > logits.Data[lastRow + best] )
best = c;
return best;
}
/// <summary>Abramowitz–Stegun erf (max error ~1.5e-7, plenty for fp32 goldens).</summary>
internal static float Erf( float x )
{
var sign = x < 0 ? -1f : 1f;
x = MathF.Abs( x );
var t = 1f / (1f + 0.3275911f * x);
var y = 1f - (((((1.061405429f * t - 1.453152027f) * t) + 1.421413741f) * t
- 0.284496736f) * t + 0.254829592f) * t * MathF.Exp( -x * x );
return sign * y;
}
}