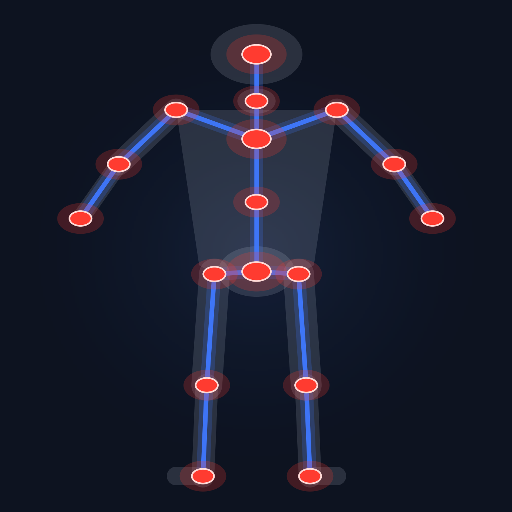
Auto Rigger
Released
deep-learning auto-rigger for s&box. Rig Everything. (experimental)
AutoRig/Dl/UniRig/OptDecoder.cs
Decoder implementation for an OPT-style transformer. Defines per-layer weight container (OptLayer), a per-layer KV cache (OptKvCache) and the OptDecoder that runs autoregressive forward passes with learned positional embeddings, multi-head attention, residuals, layer norms and an lm_head projection.
using AutoRig.Dl.Nn;
namespace AutoRig.Dl.UniRig;
using AutoRig.Dl;
/// <summary>One OPT decoder layer's weights (HF modeling_opt naming).</summary>
public sealed class OptLayer
{
public required Tensor QWeight, QBias, KWeight, KBias, VWeight, VBias, OutWeight, OutBias;
public required Tensor AttnLnGamma, AttnLnBeta; // self_attn_layer_norm (pre)
public required Tensor FfnLnGamma, FfnLnBeta; // final_layer_norm (pre-FFN)
public required Tensor Fc1Weight, Fc1Bias, Fc2Weight, Fc2Bias;
}
/// <summary>Per-layer KV cache for autoregressive decoding.</summary>
public sealed class OptKvCache
{
internal Tensor[] Keys;
internal Tensor[] Values;
public OptKvCache( int layers )
{
Keys = new Tensor[layers];
Values = new Tensor[layers];
}
/// <summary>Total cached sequence length.</summary>
public int Length => Keys[0]?.Shape[0] ?? 0;
}
/// <summary>
/// OPT causal decoder (HF modeling_opt semantics): learned positional embeddings
/// with OPT's fixed +2 offset, lm_head, embeddings consumed directly (callers
/// feed mesh latents as prefix). Layer norm placement follows the config's
/// do_layer_norm_before: UniRig uses pre-LN + top-level final norm; the real
/// opt-350m (MagicArticulate) is POST-LN with no top-level norm — set
/// <see cref="PostLn"/> and leave the final norm null.
/// </summary>
public sealed class OptDecoder
{
public required Tensor TokenEmbedding; // [vocab, hidden]
public required Tensor PositionEmbedding; // [n_positions + 2, hidden]
public required OptLayer[] Layers;
public Tensor FinalLnGamma, FinalLnBeta; // null when PostLn (opt-350m)
public required Tensor LmHeadWeight; // [vocab, hidden] (often tied)
public required int Heads;
public bool PostLn { get; init; }
public Tensor EmbedTokens( int[] ids ) => TransformerOps.Embed( TokenEmbedding, ids );
/// <summary>
/// Runs new embeddings through the decoder, appending to the cache.
/// <paramref name="positionStart"/> = absolute position of the first new row.
/// Returns logits for the new rows.
/// </summary>
public Tensor Forward( Tensor newEmbeds, OptKvCache cache, int positionStart )
{
var rows = newEmbeds.Shape[0];
var hidden = newEmbeds.Shape[1];
// Learned positions with OPT's +2 offset.
var positions = new int[rows];
for ( var i = 0; i < rows; i++ )
positions[i] = positionStart + i + 2;
var h = newEmbeds.Add( TransformerOps.Embed( PositionEmbedding, positions ) );
for ( var l = 0; l < Layers.Length; l++ )
{
var layer = Layers[l];
var residual = h;
if ( !PostLn )
h = TransformerOps.LayerNorm( h, layer.AttnLnGamma, layer.AttnLnBeta );
var q = Project( h, layer.QWeight, layer.QBias );
var k = Project( h, layer.KWeight, layer.KBias );
var v = Project( h, layer.VWeight, layer.VBias );
cache.Keys[l] = cache.Keys[l] is null ? k : cache.Keys[l].Concat( k, 0 );
cache.Values[l] = cache.Values[l] is null ? v : cache.Values[l].Concat( v, 0 );
var attended = TransformerOps.Attention(
q, cache.Keys[l], cache.Values[l], Heads, causal: true );
h = residual.Add( Project( attended, layer.OutWeight, layer.OutBias ) );
if ( PostLn )
h = TransformerOps.LayerNorm( h, layer.AttnLnGamma, layer.AttnLnBeta );
residual = h;
if ( !PostLn )
h = TransformerOps.LayerNorm( h, layer.FfnLnGamma, layer.FfnLnBeta );
h = Project( h, layer.Fc1Weight, layer.Fc1Bias ).Relu();
h = Project( h, layer.Fc2Weight, layer.Fc2Bias );
h = residual.Add( h );
if ( PostLn )
h = TransformerOps.LayerNorm( h, layer.FfnLnGamma, layer.FfnLnBeta );
}
if ( FinalLnGamma is not null )
h = TransformerOps.LayerNorm( h, FinalLnGamma, FinalLnBeta );
return h.MatMul( LmHeadWeight.Transposed );
}
static Tensor Project( Tensor x, Tensor weight, Tensor bias )
=> x.MatMul( weight.Transposed ).Add( bias );
}