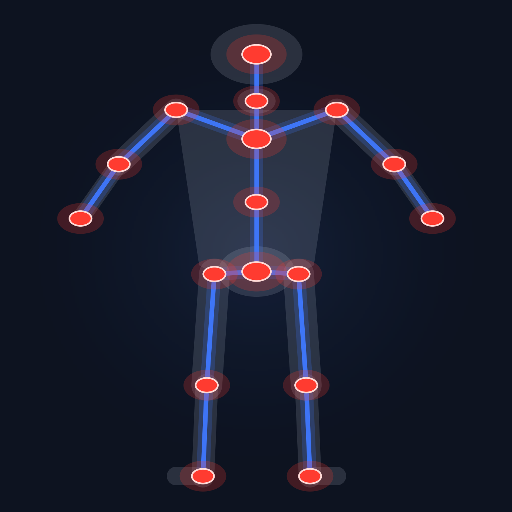
Auto Rigger
Released
deep-learning auto-rigger for s&box. Rig Everything. (experimental)
Code/AutoRig/Dl/RigNet/Layers.cs
Neural network layer implementations used by RigNet: Linear, LinearReluBn (with folded BatchNorm), Mlp stack, EdgeConv (max-aggregation over directed edges with added self-loops), and Gcu which runs two EdgeConvs and fuses their outputs.
namespace AutoRig.Dl.RigNet;
/// <summary>
/// RigNet building blocks (see docs/superpowers/rignet-port-notes.md):
/// Linear with inference-folded BatchNorm, the MLP stack, EdgeConv (max
/// aggregation over an edge list with self-loops) and the two-branch GCU.
/// </summary>
public sealed class Linear
{
public required Tensor Weight; // [out, in] (PyTorch layout)
public required Tensor Bias; // [out]
public Tensor Forward( Tensor x ) // x: [N, in] → [N, out]
=> x.MatMul( Weight.Transpose() ).Add( Bias );
}
/// <summary>Linear → ReLU → BatchNorm1d, with the batch norm folded for inference.</summary>
public sealed class LinearReluBn
{
public required Linear Linear;
/// <summary>Per-channel scale = gamma / sqrt(var + eps).</summary>
public required Tensor BnScale; // [out]
/// <summary>Per-channel shift = beta - mean * scale.</summary>
public required Tensor BnShift; // [out]
public Tensor Forward( Tensor x )
{
var y = Linear.Forward( x ).Relu();
// y * scale + shift, channel-wise on the last dim.
var cols = y.Shape[1];
var data = new float[y.Count];
for ( var i = 0; i < y.Count; i++ )
data[i] = y.Data[i] * BnScale.Data[i % cols] + BnShift.Data[i % cols];
return Tensor.From( data, y.Shape[0], cols );
}
/// <summary>Builds with BatchNorm folded from the checkpoint's running stats.</summary>
public static LinearReluBn Fold(
Tensor weight, Tensor bias, Tensor gamma, Tensor beta,
Tensor runningMean, Tensor runningVar, float eps = 1e-5f )
{
var channels = gamma.Count;
var scale = new float[channels];
var shift = new float[channels];
for ( var c = 0; c < channels; c++ )
{
scale[c] = gamma.Data[c] / MathF.Sqrt( runningVar.Data[c] + eps );
shift[c] = beta.Data[c] - runningMean.Data[c] * scale[c];
}
return new LinearReluBn
{
Linear = new Linear { Weight = weight, Bias = bias },
BnScale = Tensor.From( scale, channels ),
BnShift = Tensor.From( shift, channels ),
};
}
}
/// <summary>A stack of Linear→ReLU→BN layers (RigNet's MLP helper).</summary>
public sealed class Mlp
{
public required LinearReluBn[] Layers;
public Tensor Forward( Tensor x )
{
foreach ( var layer in Layers )
x = layer.Forward( x );
return x;
}
}
/// <summary>
/// EdgeConv (MessagePassing, aggr=max): message = mlp(concat(x_i, x_j - x_i)) over
/// directed edges j→i INCLUDING self-loops; per-node feature = max over messages.
/// </summary>
public sealed class EdgeConv
{
public required Mlp Mlp;
/// <param name="x">[N, C] node features.</param>
/// <param name="edges">Directed (source j, target i) pairs WITHOUT self-loops;
/// self-loops are added here, matching torch_geometric's add_self_loops.</param>
public Tensor Forward( Tensor x, (int From, int To)[] edges )
{
var n = x.Shape[0];
var inChannels = x.Shape[1];
// Build the message input rows: one per edge + one self-loop per node.
var messageCount = edges.Length + n;
var messageInput = new float[messageCount * inChannels * 2];
void FillRow( int row, int i, int j )
{
var baseIndex = row * inChannels * 2;
for ( var c = 0; c < inChannels; c++ )
{
var xi = x.Data[i * inChannels + c];
var xj = x.Data[j * inChannels + c];
messageInput[baseIndex + c] = xi;
messageInput[baseIndex + inChannels + c] = xj - xi;
}
}
for ( var e = 0; e < edges.Length; e++ )
FillRow( e, edges[e].To, edges[e].From );
for ( var i = 0; i < n; i++ )
FillRow( edges.Length + i, i, i );
var messages = Mlp.Forward( Tensor.From( messageInput, messageCount, inChannels * 2 ) );
var outChannels = messages.Shape[1];
// Max-aggregate messages into their target nodes.
var result = new float[n * outChannels];
Array.Fill( result, float.MinValue );
void Aggregate( int row, int target )
{
for ( var c = 0; c < outChannels; c++ )
{
var value = messages.Data[row * outChannels + c];
var at = target * outChannels + c;
if ( value > result[at] )
result[at] = value;
}
}
for ( var e = 0; e < edges.Length; e++ )
Aggregate( e, edges[e].To );
for ( var i = 0; i < n; i++ )
Aggregate( edges.Length + i, i );
return Tensor.From( result, n, outChannels );
}
}
/// <summary>
/// GCU: parallel EdgeConvs over topology and geodesic edges (each out/2 wide),
/// concatenated then fused by an MLP [out → out].
/// </summary>
public sealed class Gcu
{
public required EdgeConv Topology;
public required EdgeConv Geodesic;
public required Mlp Fuse;
public Tensor Forward( Tensor x, (int From, int To)[] topologyEdges, (int From, int To)[] geodesicEdges )
{
var a = Topology.Forward( x, topologyEdges );
var b = Geodesic.Forward( x, geodesicEdges );
return Fuse.Forward( a.Concat( b, 1 ) );
}
}