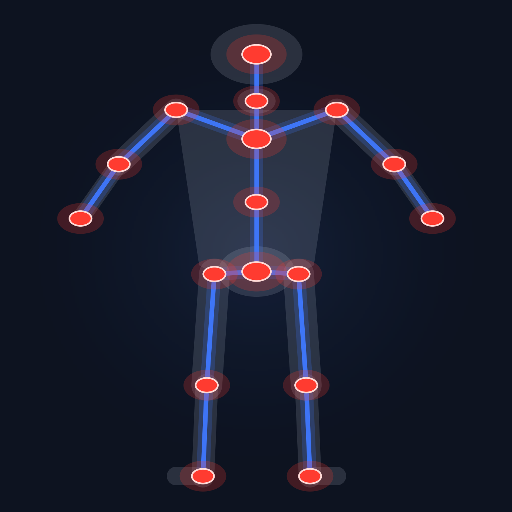
Auto Rigger
Released
deep-learning auto-rigger for s&box. Rig Everything. (experimental)
Code/AutoRig/Dl/UniRig/Qwen3Decoder.cs
Decoder implementation for the Qwen3 transformer used as an autoregressive language model. Defines a layer type with weights and RMSNorm gammas, and a Qwen3Decoder that embeds tokens, applies per-layer attention with per-head RMSNorm, rotary embeddings, grouped-query attention with KV caching, SwiGLU feedforward, final RMSNorm and a separate lm_head to produce logits.
using AutoRig.Dl.Nn;
namespace AutoRig.Dl.UniRig;
using AutoRig.Dl;
/// <summary>One Qwen3 decoder layer (HF modeling_qwen3 naming; no attention biases).</summary>
public sealed class Qwen3Layer
{
public required Tensor QWeight, KWeight, VWeight, OWeight;
public required Tensor QNormGamma, KNormGamma; // per-head RMSNorm (head_dim)
public required Tensor InputLnGamma; // input_layernorm (RMS)
public required Tensor PostAttnLnGamma; // post_attention_layernorm (RMS)
public required Tensor GateWeight, UpWeight, DownWeight;
}
/// <summary>
/// Qwen3 causal decoder (SkinTokens' backbone, 0.6B config: hidden 896, 16 q /
/// 8 kv heads × 128, SwiGLU 3072): RMSNorm pre-norms, per-head q/k RMSNorm,
/// rotary embeddings, grouped-query attention with KV cache, untied lm_head.
/// Consumes embeddings directly (mesh latents arrive as a prefix).
/// </summary>
public sealed class Qwen3Decoder
{
public required Tensor TokenEmbedding; // [vocab, hidden]
public required Qwen3Layer[] Layers;
public required Tensor FinalNormGamma;
public required Tensor LmHeadWeight; // [vocab, hidden] (untied)
public required int QHeads;
public required int KvHeads;
public float RopeTheta { get; init; } = 1e6f;
public Tensor EmbedTokens( int[] ids ) => TransformerOps.Embed( TokenEmbedding, ids );
/// <summary>Runs new embeddings through the decoder, appending to the cache;
/// returns logits for the new rows.</summary>
public Tensor Forward( Tensor newEmbeds, OptKvCache cache, int positionStart )
{
var rows = newEmbeds.Shape[0];
var positions = new int[rows];
for ( var i = 0; i < rows; i++ )
positions[i] = positionStart + i;
var h = newEmbeds;
for ( var l = 0; l < Layers.Length; l++ )
{
var layer = Layers[l];
var residual = h;
var normed = TransformerOps.RmsNorm( h, layer.InputLnGamma );
var q = normed.MatMul( layer.QWeight.Transposed );
var k = normed.MatMul( layer.KWeight.Transposed );
var v = normed.MatMul( layer.VWeight.Transposed );
// Qwen3: per-head RMSNorm on q/k, THEN rotary embedding.
q = TransformerOps.RmsNormPerHead( q, layer.QNormGamma, QHeads );
k = TransformerOps.RmsNormPerHead( k, layer.KNormGamma, KvHeads );
q = TransformerOps.Rope( q, QHeads, positions, RopeTheta );
k = TransformerOps.Rope( k, KvHeads, positions, RopeTheta );
cache.Keys[l] = cache.Keys[l] is null ? k : cache.Keys[l].Concat( k, 0 );
cache.Values[l] = cache.Values[l] is null ? v : cache.Values[l].Concat( v, 0 );
var attended = TransformerOps.AttentionGqa(
q, cache.Keys[l], cache.Values[l], QHeads, KvHeads, causal: true );
h = residual.Add( attended.MatMul( layer.OWeight.Transposed ) );
residual = h;
normed = TransformerOps.RmsNorm( h, layer.PostAttnLnGamma );
var gate = normed.MatMul( layer.GateWeight.Transposed );
var up = normed.MatMul( layer.UpWeight.Transposed );
h = residual.Add(
TransformerOps.SwiGlu( gate, up ).MatMul( layer.DownWeight.Transposed ) );
}
h = TransformerOps.RmsNorm( h, FinalNormGamma );
return h.MatMul( LmHeadWeight.Transposed );
}
}